Recuperação a Falhas
As operações envolvendo um banco de dados podem ser abruptamente interrompidas. Caso uma interrupção ocorra antes de todas as alterações referentes a uma operação serem plenamente finalizadas, confirmadas e salvas no armazenamento, o banco de dados pode entrar em um estado desorganizado e inoperante. A recuperação de falhas é o procedimento pelo qual o banco de dados á restaurado para um estado coeso e operacional. Ou seja, a recuperação de falhas existe para garantir as propriedades de atomicidade e durabilidade de transações.
Tipos de Falhas
As falhas no banco de dados que podem afetar sua integridade, segurança e desempenho podem ser divididas em 3 tipos principais:
- Falhas de Transação: ocorrem quando erros do sistema ou erros lógicos impedem de alguma forma que uma transação seja executada normalmente. Quanto aos erros, o primeiro ocorre devido a um estado inadequado do sistema, enquanto o segundo é causado por problemas internos, como dados ausentes ou programação incorreta.
- Falhas de Sistema: não causam danos físicos ao banco de dados, mas afetam todas as transações em andamento. Nesses casos, ocorre perda do conteúdo da memória de processamento, resultando na perda de informações sobre o ponto de execução dos programas e instruções manuais.
- Falha de Hardware: acontece quando um componente físico do sistema não funciona corretamente, causando perda de dados, corrupção de arquivos e instabilidades. Ela pode ser causada por desgaste, superaquecimento, problemas elétricos ou defeitos de fabricação.
Além disso, podem ser categorizadas em:
- Falha Catastrófica: Em caso de uma falha severa, o banco de dados é restaurado usando a cópia mais recente (backup), e um estado coeso é recriado ao refazer as operações das transações previamente confirmadas, utilizando informações do arquivo de registro.
- Falha Não Catastrófica: Quando ocorre uma falha menos grave, as ações são direcionadas para corrigir a inconsistência. Isso é alcançado revertendo as alterações que levaram à desordem, desfazendo operações de transações não confirmadas ou repetindo as ações de transações que já foram confirmadas.
Conceitos sobre Recuperação
Para compreender as medidas que podem ser adotadas para efetuar a recuperação após a ocorrência de falhas em bancos, é importante adquirir compreender certos conceitos.
- LOG: é uma sequência de registros que mantém um arquivo atualizado com informações sobre as atividades realizadas com os dados de um banco de dados. Ele registra as operações e alterações feitas nos dados, permitindo rastrear e recuperar essas atividades em caso de falhas ou necessidade de recuperação. Cada registro no LOG contém informações como o identificador da transação, o identificador do item de dado, o valor antigo e o valor novo associados a essa transação.
- UNDO: desfaz as alterações feitas pela transação, restaurando os valores antigos de todos os itens de dados atualizados por essa transação.
- REDO: ajusta os valores de todos os itens de dados atualizados pela transação para os novos valores.
- CHECKPOINT: são registros inseridos no log em intervalos regulares e envolvem a execução da seguinte sequência de operações: suspender temporariamente a execução de todas as transações, forçar a escrita das operações de gravação da memória principal para o disco, escrever o checkpoint no log e forçar a escrita do log no disco. Após isso, a execução das transações é retomada.
Exemplo de log no MySQL WorkBench
Redo, Undo
Na ilustração abaixo, é possível observar a execução de cinco transações distintas (T1, T2, T3, T4 e T5), ocorrendo em diferentes momentos ao longo do tempo, até que uma falha (crash) ocorra no SGBD. Durante o processo de recuperação pós-falha, as transações T1, T2 e T4 necessitam passar pelo processo de REDO. Isso é crucial para que as modificações previamente registradas no log possam ser reaplicadas, permitindo que essas transações sejam reconstruídas e suas alterações reflitam novamente no estado consistente do banco de dados.
Por outro lado, as transações T3 e T5 requerem a aplicação do processo de UNDO, uma vez que, no momento da ocorrência da falha, essas transações ainda não haviam sido confirmadas. Portanto, é necessário desfazer as alterações provocadas por essas transações, a fim de manter a integridade do banco de dados e restaurar seu estado coerente após o incidente.
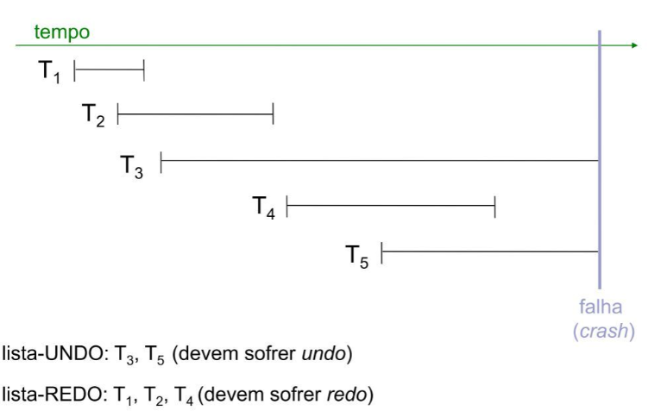
Exemplo de Undo/Redo
Checkpoint
O sistema periodicamente grava em disco os buffers alterados pelo SGBD, que são áreas temporárias de armazenamento de dados. Isso otimiza o desempenho, agrupando várias operações de gravação em uma, reduzindo a escrita direta no disco.
Essa ação gera um registro chamado checkpoint no log, marcando o estado atual do banco de dados após mudanças serem confirmadas. Esse checkpoint é vital para recuperar o sistema em caso de falha, servindo como ponto confiável para restauração.
O intervalo entre checkpoints pode ser definido pelo tempo decorrido desde o último ou pelo número de transações confirmadas. Isso equilibra a durabilidade das transações e o desempenho do sistema, garantindo eficácia na recuperação em falhas.
As ações em um processo de Checkpoint são:
- Suspender temporariamente a execução de transações.
- Gravar à força todos os buffers de memória que tenham sido modificados para o disco.
- Gravar um registro [checkpoint] no log, forçando a gravação do mesmo no disco.
- Retomar as transações em execução.
Na ilustração abaixo, há novamente uma representação visual da execução de cinco transações (T1, T2, T3, T4 e T5), sendo que desta vez um checkpoint foi estabelecido antes da ocorrência de uma falha.
Como podemos observar, as transações T1 e T2 foram executadas com sucesso e seus efeitos já foram devidamente incorporados ao Banco de Dados antes do checkpoint, tornando desnecessário o processo de REDO para essas transações. Por outro lado, a transação T4 foi concluída, no entanto, as suas atualizaçães podem ainda não estar refletidas completamente no Banco de Dados, tornando necessário o processo de REDO.
Quanto às transações T3 e T5, elas não foram finalizadas no momento da falha, o que implica que elas devem passar pelo processo de UNDO, de modo a desfazer quaisquer alterações parciais que possam ter ocorrido.
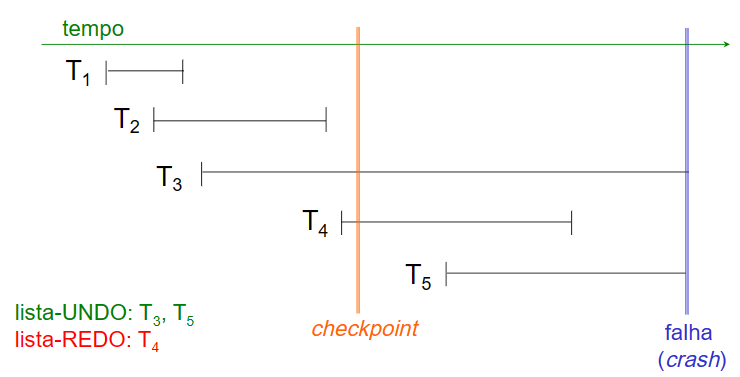
Exemplo de Undo/Redo com Checkpoint
A recuperação de falhas em bancos de dados é um processo crítico para manter a integridade e a consistência dos dados. Através das operações de UNDO e REDO, é possível corrigir alteraçães não confirmadas e reafirmar as alteraçães confirmadas, respectivamente. Os checkpoints desempenham um papel crucial, permitindo pontos confi´veis para restauração após falhas, otimizando a durabilidade das transaçães e o desempenho do sistema. Ao compreender esses conceitos e pr´ticas, podemos garantir a confiabilidade e a disponibilidade dos dados em ambientes de bancos de dados, mesmo em situações adversas.
Atividade de Fixação
No intuito de fixar a aprendizagem iniciada por meio deste módulo e verificar como está sua compreensão sobre o mesmo, são sugeridos alguns exercícios de fixação para serem resolvidos. Clique no link de exercícios ao lado, pois será por meio dele iniciada a lista de exercícios sobre os conteúdos estudados até este momento. Boa revisão sobre os mesmos!!