MODELO RELACIONAL DE DADOS
O Modelo Relacional é uma abordagem para representar dados em um BD, usando um conjunto de relações, que são frequentemente comparadas a tabelas. Cada relação contém informações sobre entidades ou relacionamentos relevantes no contexto da aplicação que está sendo modelada. Em termos simples, uma relação pode ser visualizada como uma tabela de valores, em que cada linha representa uma coleção de dados inter-relacionados.
Ele representa uma tentativa de descrever um banco de dados por conceitos matemáticos simples e bem conhecidos (álgebra relacional). A álgebra relacional é uma linguagem formal que define operações para manipular e acessar dados armazenados em relações. Essas operações incluem projeção, seleção, união, interseção e diferença, entre outras.
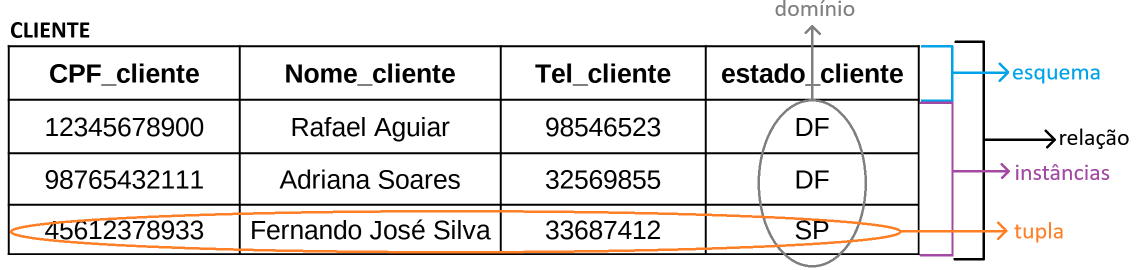
Ao nomear as tabelas e suas colunas, é possível contribuir para uma compreensão mais clara do significado dos valores armazenados em cada registro das tabelas. No universo do Modelo Relacional, cada linha de uma tabela é chamada de TUPLA, a tabela em si é referida como RELAÇÃO, o nome de cada coluna é tratado como ATRIBUTO da relação, e o conjunto de valores que um atributo específico pode assumir em uma relação é definido como seu DOMÍNIO. O domínio abrange um grupo de valores indivisíveis a partir dos quais um ou mais atributos obtêm seus valores reais. O esquema de uma relação descreve o conjunto de atributos que define as características dos elementos que est´o sendo modelados. A quantidade de atributos presentes em um esquema é referida como Grau da Relação. A cardinalidade da relação é a quantidade de tuplas, no exemplo a cardinalidade é 4. O grau da relação é a quantidade de colunas, no exemplo o grau é 3.
Uma tabela possui linhas, as quais, ao serem recuperadas pelo SGBD, não são ordenadas, portanto, não é possível referenciar linhas pelas suas posições (uso de ponteiros). Para ocorrer uma ordenação faz-se necessária uma instrução de consulta.
Os campos de uma tabela devem ser atômicos (únicos) e monovalorados (possuir apenas um valor).
Cada tabela deve ter um único nome, para que esta possa ser referenciada. Cada coluna (atributo) tem um nome que representa um aspecto do objeto representado. Cada relação (tabela) contém zero ou mais tuplas (linhas).
Restrições de integridade
Para um dado ser íntegro, ele precisa ser consistente, ou seja, ele não entra em conflito com outros dados.
As restrições de integridade se dividem em:
- Restrições de Chaves: cada atributo das chaves candidatas deve possuir valor único em todas as tuplas da relação.
- Integridade de domínio: os valores dos dados são anteriormente definidos, atômicos e obrigatórios. Exemplo: sexo é definido como 'M' ou 'F', logo os valores aceitos são somente esses;
- Integridade de vazio: nenhuma chave primária pode ser nula;
- Integridade de entidade: o nome de uma entidade tem que ser único no banco de dados;
- Integridade referencial: a chave estrangeira deve referenciar uma chave primária;
- Restrições semânticas: colocar na programação somente os termos aceitos pela linguagem.
Em um banco de dados relacional:
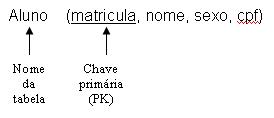
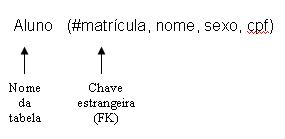
- Cada tabela é listada pelo seu nome;
- Após o nome da tabela são listados os nomes das colunas, separados por vírgula e entre parênteses;
- Os atributos que representam chave primária são sublinhados;
- Após a definição da tabela, são listadas as definições de chave estrangeira. No caso de haver mais de uma, elas serão separadas por vírgula.
Exemplos:
Atividade de Fixação
No intuito de fixar a aprendizagem iniciada por meio deste módulo e verificar como está sua compreensão sobre o mesmo, são sugeridos alguns exercícios de fixação para serem resolvidos. Clique no link de exercícios ao lado, pois será por meio dele iniciada a lista de exercícios sobre os conteúdos estudados até este momento. Boa revisão sobre os mesmos!!