TESTES EM BANCO DE DADOS - TDD
Conceitos
Para a criação de testes em bancos de dados, ou seja, testes aplicados sobre bases de dados (BD) disponibilizadas em Sistemas Gerenciadores de Banco de Dados (SGBD), é necessário, inicialmente, ter em mente o mundo real para a produção de informações as mais parecidas possíveis com a realidade, a partir da coleta de dados. O motivo para isso está na necessidade de atender as demandas exigidas por seus usuários, que podem ser abordados como clientes interessados em suas informações, além de como a aplicação se comporta para tais situações. Um exemplo prático para tal conceito será demonstrado através da modelagem para o problema sugerido a seguir:
- Suponha que seja necessário modelar uma base de dados (BD) que permita o cadastro de pessoas e seus carros, em que uma pessoa pode ser proprietário de um ou mais carros, no qual cada carro poderia ser de posse também de uma ou mais pessoas (proprietários).
A princípio três modelagens poderiam ser pensadas para esse problema proposto, sendo duas delas incoerentes (não atenderiam a demanda coerentemente) e uma correta. Para constatar se o modelo pensado compreende a necessidade do cliente, os seguintes testes foram projetados para serem realizados sobre esta BD, sendo eles:
- Inserção de uma pessoa com um único carro;
- Inserção de uma pessoa com múltiplos (mais que um) carros;
- Inserção de mais que uma pessoa como proprietária de um mesmo carro;
- Inserção de múltiplas pessoas como proprietárias de vários carros, podendo eles serem compartilhados.
Figura 1: Modelagem com relacionamento 1:n, em que uma pessoa pode possuir mais que um carro.
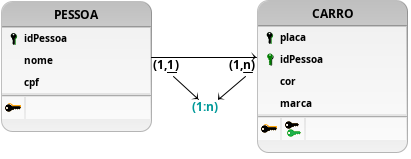
O primeiro modelo proposto, representando em um Diagrama Lógico de Dados (DLD) na Figura 1, possui como principal estratégia um relacionamento com cardinalidade 1:n entre as tabelas, provenientes das tabelas PESSOA e CARRO. Apenas com os testes descritos anteriormente é perceptível que essa modelagem não atenda às necessidades do cliente, visto que não é possível um carro ser possuído por mais de uma pessoa. Isso indica que a modelagem não é suficiente e deve ser repensada para cumprir com as necessidades apuradas para tal solução ser coerente.
Figura 2: Modelagem com relacionamento n:1, em que um mesmo carro pode ser de mais de uma pessoa.
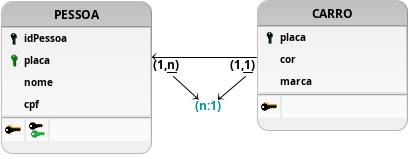
O segundo modelo proposto, e representando no DLD na Figura 2, também sofre com um problema similar ao anterior da Figura 1. Ao contrário da primeira modelagem, dessa vez a PESSOA se relaciona com o CARRO pela cardinalidade n:1, o que corrige o problema identificado na reflexão da Figura 1 e a demanda a ser resolvida. Entretanto, essa atualização impede que uma mesma pessoa possa possuir mais que um carro, falhando também na segunda proposição de testes a serem realizados.
Portanto, para suprir com os requisitos identificados para esta modelagem existe a necessidade de se adaptar às duas primeiras propostas de solução para que ambas as tabelas envolvidas, PESSOA e CARRO, tenham a capacidade de realizar relacionamentos em que a cardinalidade seja de muitos para muitos, ou seja, várias pessoas possam ser proprietárias de vários carros. Então, para atingir esse objetivo, representado na Figura 3 por um novo DLD, será preciso implementar no relacionamento possui a cardinalidade n:m, que exigirá a criação de uma nova tabela para estabelecer tal relacionamento de forma coerente ao problema apresentado.
Figura 3: Modelagem com relacionamento n:m, em que uma pessoa pode ser possuir vários carros e um carro pode ter mais que um proprietário.
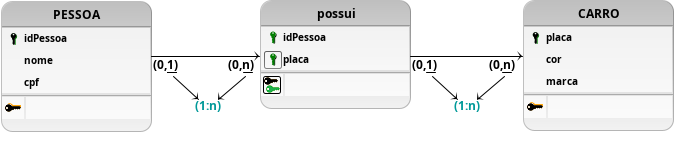
Esse novo modelo proposto permite que todos os testes pensados previamente sejam realizados, atendendo a demanda do cliente, bem como, as regras previamente estabelecidas para a implementação coerente envolvendo as duas tabelas provenientes da modelagem entidade-relacionamento das entidades PESSOA e CARRO. Vale a pena ressaltar que esses testes estão longe de serem suficientes para garantir uma modelagem minimamente efetiva para o problema proposto, visto que tipos, atributos armazenados, nomes, relacionamentos, formas normais, eficiência e diversas outras características não foram abordadas neste momento inicial de estudo e reflexão sobre a importância dos testes em banco de dados para a solução de situações a serem resolvidas de maneira coerente ao problema mapeado do mundo real.
Atributos e tipos presentes nas entidades
Diferente do primeiro exemplo abordado sobre a importância dos testes e a consciência do profissional que estará propondo uma solução coerente com a cardinalidade identificada em um ambiente já modelado, quais seriam os atributos que seriam criados para um novo projeto de banco de dados ser iniciado ?
Para isso, deve-se pensar previamente quais seriam as características que definem cada entidade a ser criada na base de dados que será proposta como solução. Um nome significativo para a entidade e cada um de seus atributos facilitará a interpretação e o entendimento do projeto como um todo, melhor garantindo a coerência com a demanda do cliente, além de facilitar bastante a sua implementação.
Com o objetivo de exemplificar essas situações poderia ser utilizado o mesmo problema abordado nas reflexões anteriores sobre as pessoas e seus carros.
Por se tratar de um problema mais simples, a sua abstração também é facilitada, entretanto a troca de alguns termos ou expressões por outras, como a substituição de pessoa por um nome específico de uma pessoa, ou a retirada de alguma de suas características pode aumentar a dificuldade de compreensão da proposta. Por exemplo, a Figura 4 procura tornar mais perceptível tal complexidade intrínseca que os nomes, também chamados de identificados, podem trazer quando não forem associados adequadamente.
Figura 4: Algumas modelagens alternativas para representação de Pessoa.
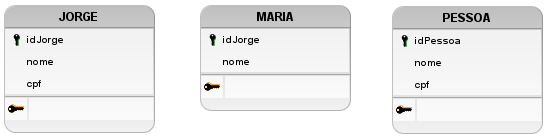
Por meio de testes, e de acordo com o problema apresentado, é perceptível que apenas uma das três modelagens atende melhor a demanda existente para PESSOA. A tabela JORGE, apresentada na primeira imagem da Figura 4, não representa corretamente, visto que é possível e será comum a adição de pessoas com nomes diferentes de Jorge, não sendo capaz de modelar com exatidão as necessidades do problema proposto.
Da mesma forma, a tabela apresentada na segunda imagem da Figura 4 sofre com a mesma deficiência, entretanto, com outros dois problemas, sendo eles:
- i) a incoerência do nome do atributo que é a chave primária (idJorge) da tabela;
- ii) a inexistência do atributo cpf, que pode trazer consequências sérias à essa abstração, principalmente se for um atributo obrigatório para a demanda do cliente.
O atributo idJorge pode ser facilmente testado, criando-se uma tabela JORGE que também possua o mesmo atributo. Essa configuração torna extremamente confusa a inserção de valores novos na base de dados para outros registros de tuplas que não serão do Jorge, por exemplo.
Dessa forma, a proposta da terceira imagem da Figura 4 seria mais coerente, sendo uma representação do mundo real que envolve aspectos genéricos significativos para a adequada compreensão do projeto modelado a partir da demanda do cliente e de seu nível conceitual elaborado a partir do Modelo Entidade-Relacionamento (ME-R) e do Diagrama Entidade-Relacionamento (DE-R). Assim, as expressões que identificam os nomes das tabelas e seus atributos serão significativos a compreensão de qualquer profissional da área, tornando mais fácil o entendimento da solução elaborada.
A coerente identificação do tipo de dado para cada atributo também é relevante na definição das características de armazenamento e manipulação possível do que estará sendo armazenado em cada tabela existente em um projeto de banco de dados. Tal importância pode ser observada no exemplo abordado a seguir.
- Imagine que se deseja armazenar os seguintes dados para cada conta bancária, sendo então os atributos para cada cliente: cpf, agência, conta e data de criação (abertura) da conta. Os valores de agência e conta deverão também armazenar os seus respectivos dígitos verificadores para serem armazenados com segurança.
Da mesma forma, utilizando-se do TDD (Test Driven Development), foram elaborados os seguintes testes para validar a coerência e da modelagem proposta como solução para o problema proposto:
- Os atributos cpf, agência e conta só devem aceitar números;
- Os atributos devem utilizar o menor espaço válido de armazenamento possível;
- A data de criação (abertura da conta) deve possuir um dia, um mês e um ano válido.
Figura 5: Modelagem com os atributos cpf e digito_conta do tipo varchar.

Inicialmente, três alternativas foram pensadas para a modelagem que guardaria os dados relevantes para cada conta corrente que seria criada no projeto de banco de dados que melhor solucionaria tal demanda do cliente. A primeira imagem da Figura 5 não seria adequada, pois possui o atributo cpf e a agência com o tipo de dado que armazena qualquer tipo de caracter aceito pelo computador (varchar) e não somente valores numéricos. Na compreensão da demanda do cliente foi identificado que estes atributos só poderiam aceitar valores numéricos, o que então contraria tal requisito importante para solução do problema proposto.
Figura 6: Modelagem com o atributo cpf restringindo o tamanho do seu conteúdo
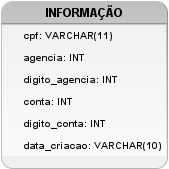
Apesar disso, vale a pena analisar as demais afirmações para se obter um entendimento mais completo das necessidades de tal demanda. Assim, observando a proposta de solução da imagem na Figura 6 o atributo cpf está restrito até 11 caracteres, que podem armazenar valores diferentes de números. Com isso, o cliente poderia incluir símbolos diferentes de números, como o ponto e o traço (hífen) para separar o dígito verificador presente em todo cpf. Com tais digitações sendo possíveis, o CPF possuiria mais que 11 caracteres e a segunda proposta também não seria adequada para resolver o problema proposto.
Analisando ainda a Figura 5, mas observando o atributo conta, que corresponderia ao número da conta bancária a ser criada e armazenada na base de dados, foi definido um tipo de dado coerente que só aceita valores numéricos, mas não seria adequado porque o tipo de dado indicado possui um limite em seu armazenamento que o tornaria incoerente. O tipo de dados TINYINT, disponível em vários bancos de dados, guarda valores até 127, existindo uma expectativa para a solução da demanda do cliente que existiram bem mais do que 127 contas criadas somente.
Figura 7: Modelagem com o atributo de data do tipo date.

Outra variação a ser ressaltada nas variações de possíveis soluções presentes na Figura 7 está no atributo que armazena a data de criação (abertura) da conta. Na primeira e segunda imagens o tipo de dado armazena qualquer caractere ou símbolo aceito por um computador, existindo variação no tamanho de cada uma das propostas. Na terceira proposta presente na Figura 7 o tipo de dado adequado para o armazenamento coerente de somente datas válidas é utilizado no atributo que tem a responsabilidade de guardar a data de criação da conta, deixando as duas primeiras propostas inadequadas para atendimento à demanda. Por exemplo, somente a terceira opção não aceita a data do dia 30 de fevereiro de 2001.
Uma outra reflexão interessante na comparação da segunda e terceira imagens da Figura 7 para uma proposta de solução adequada estaria na análise dos atributos que teriam a responsabilidade de armazenar os dígitos verificadores de agência e conta. Note que os tipos de dados entre as duas propostas destacadas nesta análise, Figuras 5 e 6, os tipos de dados são diferentes. Sabendo que cada atributo só armazenará um único número de uma casa só para cada dígito, então o tipo INT se torna muito grande para tal armazenamento. Como abordado anteriormente, o tipo TINYINT teria uma precisão menor e consumiria menos espaço que o tipo INT no armazenamento do computador, atendendo coerentemente a demanda do problema proposto.
Assim, no teste da proposta de solução seria possível diminuir o espaço utilizado avaliando-se os atributos dígito da agência e dígito da conta, ao qual a correta definição do tipo de dado adequado evitaria evitaria o desperdicio desnecessária para o armazenamento de cada um destes dados no banco de dados.
No entanto, a terceira imagem da Figura 7 ainda não atende a definição de nomes significativos para a tabela e alguns de seus atributos não poderão ser criados em alguns bancos de dados que não aceitam o caractere underline na definição de seus atributos ou tabelas. Assim, nenhuma das propostas estaria aprovada nos testes pré-definidos.
Figura 8: Modelagem com atributos com nomes que melhor atendem os SGBDs.

Portanto, a modelagem que melhor resolve o problema proposto, atendendo todos os testes pré-definidos e as restrições em relação aos caracteres dos SGBDs, seria a proposta da Figura 8, que utiliza o tipo SMALLINT para o atributo conta. Este tipo de dado também está disponível em alguns bancos de dados e corresponderia a uma consulta de espaço para armazenamento menor que o tipo INT, mas um pouco maior que o tipo TINYINT
Ainda acerca dos atributos, outra característica muito importante são as restrições aplicadas. Essas restrições variam desde a obrigatoriedade de um atributo ter que ser informado até validações complexas que garantem a integridade dos dados que serão armazenados por uma ou mais tabelas em uma base de dados. Para demonstrar essa importância, é possível acrescentar três novos testes melhorando a modelagem apresentada no exemplo anterior da Figura 8, além de evoluir para a codificação do problema em MySQL.
- O atributo cpf não pode ser vazio;
- O conjunto de atributos conta e dígito da conta devem ser únicos por tabela;
- A data de criação deve estar no seguinte formato AAAA-MM-DD, significando A para ano, M para mês e D para dia;
- A identificação específica por nome para cada restrição implementada na BD.
Script 1: Solução utilizando valor default para o cpf.
CREATE TABLE CONTA (
cpf BIGINT DEFAULT 12345678910,
agencia SMALLINT,
digitoAgencia TINYINT,
conta SMALLINT,
digitoConta TINYINT,
dataCriacao VARCHAR(10)
);
Observando a modelagem que será implementada pelo Script 1 é facilmente perceptível que todos os testes irão falhar. A utilização do valor padrão (default) garante que o atributo cpf nunca será vazio, ao custo que sempre que não for fornecido um valor para o cpf lhe será atribuído 12345678910, invalidando sua obtenção para o processamento coerente com a realidade do mundo real. Para o número da conta e seu dígito não existe uma segurança implementada que garanta que uma conta não se repita, ou seja, poderão existir armazenadas contas iguais na tabela, quando na verdade o problema proposto esclareceu que uma conta com seu dígito nunca poderá se repetir.
Na definição para o atributo da data de criação não existe nenhuma verificação, ou restrição, que exija que serão fornecidos somente valores que correspondam a uma data com ano de quatro dígitos, mês de até dois e dia com até dois dígitos, podendo ser informado qualquer caractere válido para o computador devido ao tipo de dado definido como varchar. A formatação de como esta data será informada também não será verificada para ser armazenada corretamente.
Script 2: Evolução utilizando a restrição unique.
CREATE TABLE CONTA (
cpf BIGINT NOT NULL,
agencia SMALLINT,
digitoAgencia TINYINT,
conta SMALLINT,
digitoConta TINYINT,
dataCriacao DATE,
UNIQUE (conta, digitoConta)
);
Diferente do Script 1, o Script 2 apresenta uma proposta de implementação para uma modelagem mais concisa e parecendo coerente ao problema proposto, pois o armazenamento do cpf não atribui qualquer valor e através da expressão NOT NULL está sendo definida a restrição de obrigatoriedade no fornecimento de um valor para cpf, assim, o cpf nunca poderá ser vazio.
Mas observe que ainda existe a descrição de outra restrição no Script 2 que indica que a concatenação do valor armazenado no atributo conta com o valor do atributo digitoConta serão únicos nesta tabela, ou seja, não existirá nenhuma conta combinada com o dígito da conta que sejam iguais nesta tabela. Essa restrição é indicada pela palavra reservada UNIQUE, que comunica ao SGBD que para tal tabela nunca existirá a combinação do atributo conta e dígito da conta que sejam iguais.
Script 3: Melhoria nomeando a restrição que garante a unicidade.
CREATE TABLE CONTA (
cpf BIGINT NOT NULL,
agencia SMALLINT NOT NULL,
digitoAgencia TINYINT NOT NULL,
conta SMALLINT NOT NULL,
digitoConta TINYINT NOT NULL,
dataCriacao DATE NOT NULL,
CONSTRAINT conta_UK UNIQUE (conta, digitoConta)
);
No entanto, o último teste proposto não será atendido, pois a implementação da restrição UNIQUE não terá nenhum nome que o identifique rapidamente quando ele for aplicado e restringir uma operação sobre a tabela. Por isso a implementação adequada para esta restrição está indicada no Script 3. Note que no Script 3 a restrição de obrigatoriedade também está implementada de maneira coerente a demanda do cliente, pois para armazenar um cpf na tabela também deverão ser obrigatórios todos os demais atributos para se conhecer a conta, agência e data da criação.
Procurando satisfazer todos os testes propostos existe ainda a necessidade do armazenamento de uma data correta e respeitando uma formatação de data que o cliente deseja que seja respeitada para ser guardada pelo SGBD. A aplicação do tipo adequado, date, para se guardar uma data válida é essencial, embora pudesse também ser armazenado pelo tipo varchar no tamanho coerente, mas com a definição de mais uma restrição de verificação, ou checagem (check), que exigiria a definição de uma expressão regular (regex) para a data seguisse um determinado padrão, formatação ou máscara definida para este tipo de dado.
Relacionamentos entre entidades
Após as validações e modelagens dos atributos de uma entidade, parte-se para a fase de relacionamento entre as partes. Ou seja, serão analisadas e elaboradas lógicas que explicam e estruturam as interações entre as entidades de um projeto representando o que acontece no mundo real. Na área de bancos são três os principais relacionamentos que podem ser representados, respeitando as suas características específicas, sendo eles identificados, mais comumente como: um para um (1:1), uma para vários ou vários para um (1:n ou n:1) e muitos para muitos (n:m). Para demonstrar a aplicação do TDD no relacionamento um para um, o seguinte exemplo foi elaborado:
- Em uma escola cada aluno deve possuir cadastrados seu ano letivo, turma e matrícula. Cada aluno também terá informações pessoais de nome, cpf e idade armazenadas no banco de dados. É importante ressaltar que nessa escola uma pessoa só poderá estar sendo aluno uma única vez (só possuirá uma matrícula).
Para tal exemplo, os seguintes testes foram pensados:
- Um aluno é/foi exclusivamente uma única pessoa;
- Uma pessoa é/foi exclusivamente um aluno;
Figura 9: Primeira modelagem proposta para o problema, com cardinalidade 1:1.
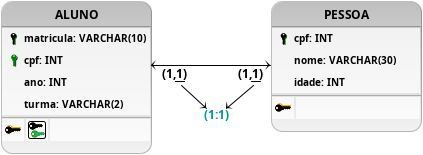
De acordo com a modelagem apresentada na Figura 9, a criação de uma chave estrangeira na tabela ALUNO permite que a solução armazene pessoas que foram alunos diversas vezes, similar ao relacionamento um para muitos, não solucionando os critérios de aceitação propostos pelo cliente. Em contrapartida, os testes são parcialmente atendidos, pois a direção desse relacionamento, chave estrangeira de PESSOA em ALUNO, impede que os alunos sejam múltiplas pessoas diferentes. Além disso, essa modelagem bloqueia a possibilidade de um ALUNO não ser uma PESSOA, caso a restrição NOT NULL seja aplicada corretamente no atributo que armazena a chave estrangeira. Tal restrição de obrigatoriedade é importante de ser implementada porque somente a definição de chave primária exige que o atributo, ou atributos se for uma chave primária composta, seja obrigatória. As chaves estrangeiras e as chaves candidatas (UNIQUE) não são obrigatórias por definição, sendo então uma definição a ser determinada pelo projeto proposto como solução adequada ao problema apresentado pelo cliente que também deve ser testada para o sucesso do projeto.
Figura 10: Tentativa de evolução da modelagem 1:1, mas com a inversão da chave estrangeira.
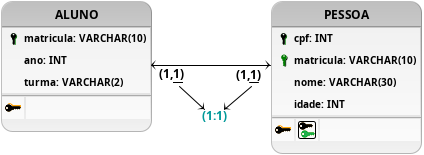
De uma forma similar, a modelagem destacada na Figura 10 busca corrigir o erro do relacionamento demonstrado na imagem anterior (Figura 9). Alterando-se a chave estrangeira do relacionamento, cpf da tabela ALUNO para a matricula da PESSOA, a resolução passa a impedir que pessoas sejam múltiplos alunos. Porém, essa alteração introduz um comportamento característico de um relacionamento um para muitos, que possibilita que os alunos correspondam a múltiplas pessoas. Portanto, essa modelagem também acaba atendendo apenas parcialmente os testes elaborados, não sendo coerente de ser implementada.
Figura 11: Modelagem 1:1 que atende o problema proposto.
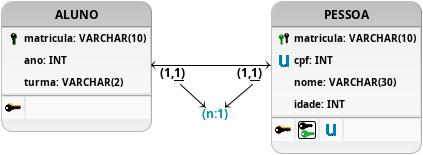
Essas falhas observadas são corrigidas na última proposta de modelagem apresentada pela Figura 11, que altera a chave primária da tabela PESSOA, bem como, acrescenta a restrição UNIQUE no atributo que armazena o cpf. As mudanças garantem que os testes sejam atendidos, já que passam a permitir que:
- i) Uma nova tupla na tabela PESSOA seja criada apenas quando um aluno já exista, caso a restrição NOT NULL seja implementada corretamente no atributo matricula;
- ii) Um pessoa seja apenas um aluno e o seu inverso também (aluno seja apenas uma pessoa), em decorrência das chaves primárias e da existência da restrição UNIQUE, que impede a existência de múltiplas matrículas na tabela PESSOA.
O segundo tipo de relacionamento que é possível em uma base de dados é o um para muitos, e vice e versa (muitos para um). Nesse relacionamento uma única entidade estará se relacionando com várias outras, sendo de extrema importância identificar qual delas estará armazenando a chave estrangeira em seu esquema para o estabelecimento do relacionamento desejado. O seguinte exemplo foi pensando para demonstrar esse relacionamento com cardinalidade de um para muitos:
- Deseja-se armazenar somente uma lista telefônica com todos os contatos de uma determinada pessoa. Os contatos deverão conter o número telefônico e o nome, enquanto a lista deverá armazenar o endereço de email do usuário e um texto descritivo sobre esta pessoa.
Seguindo o TDD, os seguintes testes foram pensados:
- Garantia que todos os contatos pertençam exclusivamente a uma lista telefônica, ou seja, o mesmo contato não pode estar em várias listas.
- Garantia que a lista armazene vários contatos.
Figura 12: Modelagem inicial sem relacionamentos.
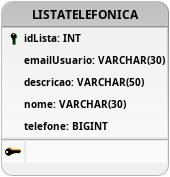
Testando-se a primeira modelagem apresentada na Figura 12 é perceptível que o armazenamento do telefone em um atributo único possui similaridades com as ideias propostas pelo relacionamento um para um. O motivo para isso está na necessidade que a modelagem possui para armazenar múltiplos contatos, pois sempre será necessária uma nova tupla na tabela LISTATELEFONICA para armazenar um novo contato. Essa incapacidade de armazenar vários contatos para uma única lista não permite que a pessoa salve todos os seus contatos, falhando com os requisitos propostos para a solução. Além disso, essa tabela não garante que o mesmo telefone seja salvo para múltiplas listas, porque não existe uma restrição que impeça esse comportamento.
Figura 13: Evolução da modelagem com nova tabela CONTATO.
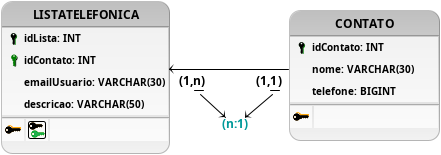
De forma similar, a modelagem proposta na Figura 13 possui um resultado similar ao obtido anteriormente em relação aos testes propostos para esse problema. Apesar dessa nova modelagem fazer o uso do relacionamento n:1 entre as tabelas LISTATELEFONICA e CONTATO, as listas telefônicas continuam apenas armazenando um único contato já que a chave estrangeira do contato está sendo salva nas tuplas da tabela LISTATELEFONICA, impedindo múltiplos contatos de serem vinculados a uma única lista telefônica. Da mesma forma, essa solução falha em garantir que cada contato seja exclusivo para cada lista, pois a restrição de integridade referencial aplicada nesta proposta permite que uma tupla da tabela CONTATO se relacione com várias outras da tabela LISTATELEFONICA.
Figura 14: Solução para o problema da Lista Telefônica.
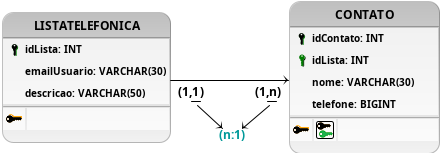
Portanto, a modelagem que melhor atende todos os requisitos demonstrados pelos testes é a disposta na Figura 14, em que o atributo idLista é salvo como chave estrangeira na tabela CONTATO. Essa inversão na direção do relacionamento 1:n não apenas garante que, agora uma lista telefônica poderá estar armazenando mais de um contato, pois não está mais restrita pela chave primária dos contatos, como também garante que uma tupla da tabela CONTATO interaja unicamente com uma lista, atendendo os requisitos elicitados para esse problema, podendo ser obrigatória a definição da lista ao qual o contato faz parte.
Caso não seja obrigatória a definição da lista por contato existirá a possibilidade de se cadastrar um contato que não pertença a nenhuma lista. Se tal situação for desejada pelo cliente então deverá ser definida a restrição de obrigatoriedade correspondente à demanda dele para a implementação do projeto.
Por fim, entre os possíveis relacionamentos que podem ser utilizados em uma modelagem resta aquele com cardinalidade muitos para muitos. Para uma reflexão educacional sobre os testes com essa cardinalidade a proposta envolveria duas entidades com características próprias no relacionando em que uma nova tabela, responsável pela associação (relacionamento) entre estas tabelas, seria necessária a criação. Para representar essa característica, o seguinte exemplo pode ser utilizado para melhor ilustrar tal situação:
- É necessário desenvolver uma aplicação que controle times de futebol e seus jogadores, em que seja possível um jogador participar de múltiplos times, pois em sua carreira poderá atuar em mais que um time, bem como, os times também deverão possuir múltiplos jogadores na sua composição (cada time terá mais que um único jogador).
Para validar o problema apresentado, os seguintes testes foram elaborados:
- Um time deve ser capaz de possuir múltiplos jogadores;
- Um jogador deve ser capaz de atuar em múltiplos times em sua carreira.
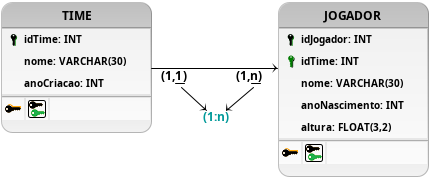
Figura 15: Primeira modelagem para o problema do time com o relacionamento n:1.
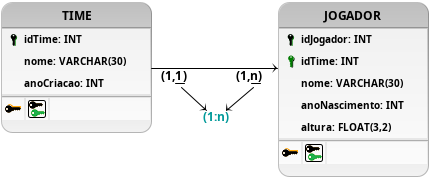
Seguindo-se os passos do TDD e aplicando os testes, é perceptível que a primeira modelagem, disposta na Figura 15, atende um dos aspectos esperados para essa solução, sendo ela a possibilidade de um jogador participar de múltiplos times ao longo de sua carreira. Essa característica é promovida pelo relacionamento n:1 entre as tabelas TIME e JOGADOR, em que um jogador pode ser referenciado pela chave estrangeira idJogador disposta nas tuplas da tabela TIME. Entretanto, essa abstração não garante, e até mesmo limita, que o inverso também seja possível e correto, ou seja, um time possuir diversos jogadores. Dessa forma, essa solução não consegue suprir com as necessidades nem com os testes elaborados para o problema.
Figura 16: Tentativa de evolução da modelagem com inversão da cardinalidade do relacionamento inicialmente proposto.
De forma similar, a modelagem apresentada na Figura 16 segue com os mesmos princípios do relacionamento um para muitos entre suas tabelas participantes. Porém, ao contrário da solução apresentada na Figura 15, a direção do relacionamento desta vez favorece as tuplas da tabela TIME, permitindo suas interações com múltiplos jogadores. Isso gera um problema similar ao identificado anteriormente, em que a utilização da chave estrangeira na entidade jogador impede que o mesmo possa jogar em vários times, já que a restrição na tabela JOGADOR impede esse relacionamento de muitos para muitos. Assim, tal alternativa também não atende as necessidades do cliente na proposta da Figura 16.
Figura 17: Adição de tabela associativa para o relacionamento n:m.
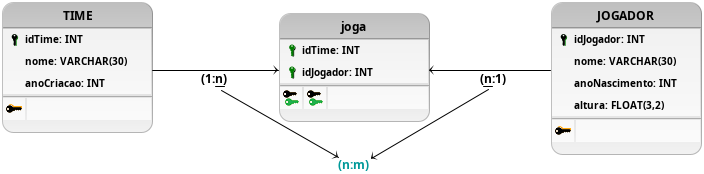
Com isso, a utilização de uma tabela associativa, denominada joga na Figura 17, permite que esses problemas sejam contornados, de forma a atender a demanda completamente do cliente. A utilização dessa nova tabela (joga), exigida nos relacionamentos com cardinalidades de muitos para muitos (n:m), traz consigo os efeitos positivos de ambas modelagem anteriores, de forma que diversos times poderão estar interagindo com vários jogadores, além de evitar as restrições propostas pelos relacionamentos um para muitos ou muitos para um.
Por ser uma definição ainda vaga, não existe a necessidade da implementação de restrições mais complexas, além daquelas que garantem a integridade referêncial na tabela joga, ou novos atributos em cima da tabela gerada pelo relacionamento muito para muitos, porém é sempre bom ter em mente que essas características podem ser transformadas em testes para melhor validar o modelo proposto, procurando garantir o seu sucesso.
Formas normais
O seguimento às regras e a rigidez muitas vezes se encontram presentes no desenvolvimento de banco de dados relacionais. Um dos principais motivos para isso, se encontra na necessidade de um mapeamento eficiente dos atributos presentes em uma modelagem, resultando dessa forma em um esquema que representa os dados de uma forma consistente e com o mínimo de redundância possível, além de garantir o seguimento às demandas do problema.
Para isso, uma das principais atividades que podem ser realizadas durante a elaboração de uma base de dados é a normalização. Esse processo gera a decomposição das tabelas já existentes em novas relações que podem garantir uma melhor construção do esquema. Dentro desse contexto, três principais regras podem ser seguidas, a primeira, a segunda e a terceira Forma Normal.
A primeira forma normal (1FN) consiste na atomicidade dos atributos, ou seja, todo atributo em um projeto de banco de dados que respeita a primeira forma normal deve ser simples e indivisível, garantindo que uma tabela seja construída sem atributos compostos ou multivalorados. Um exemplo simples e eficiente de se demonstrar essas características seria o seguinte:
- É necessário modelar uma solução capaz de armazenar múltiplos números de celular possíveis para uma determinada pessoa. Além disso, cada valor salvo deve garantir que os telefones possuam o prefixo do país (DDI), o DDD do estado e número em si.
Portanto, para validar a modelagem os seguintes testes podem ser utilizados:
- É necessário garantir que uma pessoa tenha múltiplos telefones armazenados.
- Deve ser garantido que o DDI, o DDD e o número estejam armazenados, de forma que possam ser acessados separadamente.
- Os atributos devem ser atômicos e o projeto deve estar na primeira forma normal.
Figura 18: Modelagem inicial para o problema com apenas uma tabela proveniente da entidade PESSOA.

Aplicando os testes na primeira modelagem, disposta na Figura 18, é possível notar um comportamento muito similar com o relacionamento um para um, visto que para se adicionar um número de telefone é necessário adicionar uma nova tupla na tabela PESSOA. Isso impede que a solução seja capaz de armazenar vários telefones para uma única pessoa, não atendendo um dos requisitos propostos para o problema. Além disso, os valores são guardados de uma forma agrupada, o que não permite o acesso atômico aos elementos que compõem esse dado, falhando assim nos demais testes.
Figura 19: Evolução da modelagem com adição de um relacionamento 1:n.
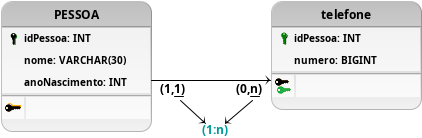
A segunda modelagem apresentada na Figura 19 consegue contornar alguns dos problemas previamente apresentados implementando um relacionamento 1:n, com a criação de uma nova tabela chamada telefone que armazena o número e uma referência para a pessoa que possui aquele dado. Essa alteração não apenas permite que uma pessoa possua múltiplos telefones, como também aumenta a atomicidade do projeto decompondo o atributo multivalorado em uma nova tabela. Entretanto, assim como na modelagem anterior o problema relacionado a composição do atributo numero ainda se encontra presente, não permitindo que esse projeto se encontre na primeira forma normal para o armazenamento demandado (DDI, DDD e o número do telefone).
Figura 20: Desenvolvimento final da modelagem com a decomposição do telefone.
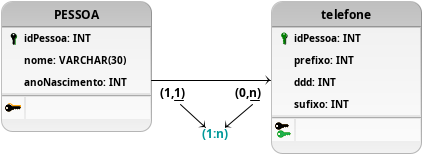
Portanto, para contornar esses problemas a proposta ilustrada na Figura 20 demonstra um esquema que garante tanto o armazenamento de múltiplos telefones, como dos seus atributos específicos decompostos em uma entidade específica. Além disso, é garantido que nesse modelo os atributos se encontram mais atômicos que os anteriores, atendendo a primeira forma normal esperada.
A segunda forma normal (2FN) tem como obrigatoriedade a normalização pela primeira forma (regra), ou seja, uma modelagem normalizada com a segunda forma normal, primeiramente, precisa atender a 1FN. Além disso, é necessário que todos os atributos que não sejam chave primária na entidade responsável pela tabela que será criada, dependam diretamente da chave primária. O seguinte exemplo, permite demonstrar e constitui uma base interessante para testes que compreendem a segunda forma normal:
- É necessário desenvolver uma aplicação capaz de armazenar professores, com matrícula, nome e formação, bem como, as matérias que lecionam contendo código único, nome da matéria e quantidade de alunos.
Com isso, os seguintes testes foram pensados:
- Deverá ser permitido o registro de múltiplas matérias para um único professor.
- Os atributos devem depender diretamente das suas chaves primárias e serem o mais simples em cada tabela do projeto.
Figura 21: Modelagem inicial contendo uma única tabela no projeto.
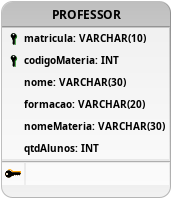
Seguindo os testes apresentados, a modelagem evidenciada na Figura 21 é capaz de armazenar múltiplas matérias, bem como vários professores, porém a eficiência e a redundância dos dados nessa tabela seria incoerente a uma proposta eficiente, pois a mesma não atenderia ao segundo teste proposto. Isso decorre da dependência direta dos atributos nome e formacao ao atributo matricula, presente na chave primária composta proposta nesta tabela Professor. O atributo nome da matéria e a quantidade de alunos (qtdAlunos) fazem referência ao atributo codigoMateria que também compõe a chave primária composta. Como resultado, será sempre necessário a inclusão de uma nova tupla na tabela com parte de suas informações duplicadas (redundantes) para quando for preciso inserir uma nova matéria para um mesmo professor ou vice e versa (um mesmo professor para outra matéria).
Não sendo então satisfatória a proposta da Figura 21 ela foi evoluída para o que está apresentado na Figura 22.
Figura 22: Evolução da modelagem contendo um relacionamento n:1.
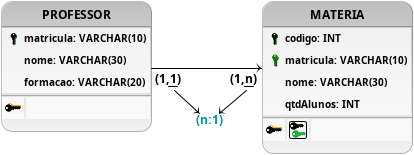
Portanto, a modelagem da Figura 22, assim como sua antecessora, garante o registro múltiplo de matérias para um determinado professor. Porém, ao contrário da modelagem previamente apresentada na Figura 21, essa evolução da Figura 22 emprega conceitos do relacionamento um para muitos (1:n) dividindo os registros em duas tabelas importantes: PROFESSOR e MATERIA. Através dessa nova modelagem os atributos passam a depender diretamente das chaves primárias de suas respectivas tabelas somente, garantindo que o segundo teste proposto seja atendido. É importante ressaltar que para isso ser possível o esquema já se encontrava com os atributos o mais simples (atômicos) possíveis, atendendo a 1FN e em sucessão a 2FN.
Dessa forma, assim como a 2FN, a Terceira Forma Normal também possui obrigatoriedade com as demais formas anteriores, portanto, para uma modelagem respeitar a Terceira Forma Normal (3FN) a 1FN e 2FN já devem ter sido respeitadas. A 3FN, por sua vez, garante que os atributos de uma tabela serão funcionalmente independentes uns dos outros, ou seja, não possuirão dependências transitivas ou indiretas entre si. Para demonstrar essa característica o seguinte problema foi elaborado:
- É necessário criar uma aplicação capaz de armazenar e disponibilizar os seguintes dados de uma parcela: taxa, juros, multa, valor bruto e valor líquido, em que o valor líquido corresponde à uma composição da taxa, juros, multas e do valor bruto envolvido.
Para validar o problema abordado os testes a seguir podem ser utilizados:
- Os atributos devem estar atômicos (simples).
- Os atributos devem ser apenas dependentes diretos da chave primária.
- É necessário que os dados sempre estejam atualizados e consistentes.
Figura 23: Modelagens alternativas para a tabela que armazena parcelas.

Aplicando-se os testes nas modelagens dispostas na Figura 23 é perceptível que no primeiro esquema todos os atributos se encontram o mais atômicos possíveis de acordo com o problema, além de todos esses atributos possuírem dependência direta da chave primária da tabela (idParcela nas duas propostas). Entretanto, a existência do atributo que armazena o valor líquido cria uma dependência transitiva com os demais atributos (taxa, juros, multa e valor bruto), indo em contrapartida ao conceito definido pela 3FN. Com isso, a atualização de alguns desses atributos não garante que o valor líquido permaneça consistente e correto de acordo com a equação definida para o mesmo, invalidando o terceiro teste apresentado para esse modelo.
De maneira contrária, a segunda tabela proposta da Figura 23 contorna esses problemas, removendo o atributo que armazena o valor líquido, levando-o para a camada de negócios a responsabilidade pelo seu cálculo e não o armazenando. Tal decisão não apenas garante que a atualização permita a consistência dos valores armazenados, mas também a normalização de acordo com a 3FN dessa base de dados, visto que a mesma já se encontrava respeitando a 1FN e a 2FN, conforme validado pelo primeiro e segundo testes elaborados para esse problema.
Dessa forma, a proposta estaria respeitando os testes e as três primeiras formas normais com a segunda imagem da Figura 23.
Atividade de Fixação
No intuito de fixar a aprendizagem iniciada por meio deste módulo e verificar como está sua compreensão sobre o mesmo, são sugeridos alguns exercícios de fixação para serem resolvidos. Clique no link de exercícios ao lado, pois será por meio dele iniciada a lista de exercícios sobre os conteúdos estudados até este momento. Boa revisão sobre os mesmos!!