ÍNDICE
Em estruturas de dados, um índice representa uma referência vinculada a uma chave de procura ou chave de acesso, empregando-se para aprimorar o desempenho das consultas e permitir a recuperação mais eficiente de registros. A chave de procura refere-se ao valor usado para referenciar um registro específico dentro de uma estrutura de dados ou tabela. Teoricamente, um índice é uma estrutura que facilita o acesso a um item indexado com uma complexidade de busca inferior à linear, podendo-se manifestar em formas logarítmicas ou constantes. No contexto dos bancos de dados, o índice toma forma de uma estrutura auxiliar, frequentemente na forma de um arquivo, associando-se a uma tabela específica. Sua finalidade é otimizar o tempo de acesso às linhas da tabela, criando ponteiros direcionados diretamente aos dados em colunas específicas, com base nas chaves de acesso. O uso de índices em bancos de dados remete à analogia com as placas de sinalização em supermercados; nelas, o banco de dados, ao identificar um produto pelo índice e com base na chave de procura, reconhece sua localização em um corredor específico, permitindo uma busca de produtos mais eficaz.
Nos supermercados, as variedades de produtos são organizadas e identificadas por placas de sinalização nos corredores, indicando categorias como "massas", "cereais" e "produtos de limpeza". Cada produto, atuando como chave de acesso, está vinculado à prateleira ou seção onde se encontra. Esta organização possibilita a identificação eficiente dos produtos, pois ao consultar as placas de sinalização por categoria, os clientes podem facilmente encontrar o corredor correspondente e localizar o item desejado.
 |
Com intuito de apoiar o aprendizado em Banco de Dados, sugere-se assistir a videoaula para o aperfeiçoamento no conhecimento deste conteúdo. |
Tipos de indices
Os índices podem ser categorizados em dois tipos principais: clusterizados e não clusterizados.
Índice Clusterizado
- Funcionamento
Um índice clusterizado determina a ordem física dos dados em uma tabela. Ou seja, a maneira como os registros são armazenados no disco corresponde à ordem do índice clusterizado.
- Características e Vantagens
- Ordenação física de registros
- Ao usar um índice clusterizado, os registros são fisicamente armazenados na ordem do índice.
- Recuperação rápida
- As consultas que seguem a ordem do índice podem ser extremamente rápidas, já que os dados adjacentes são frequentemente lidos juntos.
- Único por tabela
- Só pode haver um índice clusterizado por tabela, pois define a ordem física dos registros.
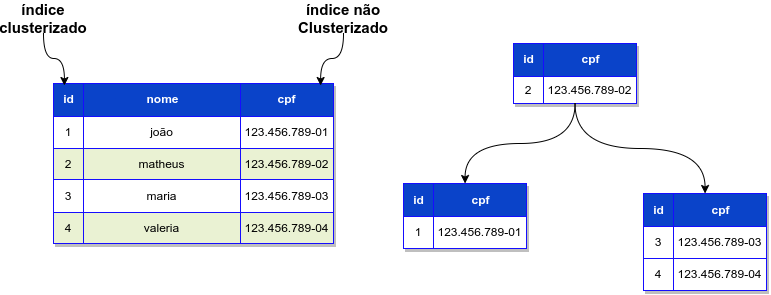
Índice Não-Clusterizado
- Funcionamento
Diferente do clusterizado, o índice não-clusterizado não reorganiza os registros físicos. Em vez disso, ele mantém um apontamento para os registros, como um índice de livro.
- Características e Vantagens
- Estrutura separada
- Mantém uma estrutura separada da tabela de dados original.
- Múltiplos por tabela
- É possível ter vários índices não-clusterizados para uma única tabela.
- Flexibilidade
- Pode-se otimizar diferentes consultas criando índices não-clusterizados em diferentes colunas.
Com base nessas duas categorias fundamentais, emergem diversas abordagens de indexação.
|
Com intuito de apoiar o aprendizado em Banco de Dados, sugere-se assistir a videoaula para o aperfeiçoamento no conhecimento deste conteúdo. |
Índice em Árvore B
- Funcionamento
A Árvore B é uma árvore balanceada onde todos os caminhos da raiz até qualquer folha possuem o mesmo comprimento. Diferente das árvores binárias, que têm nós com no máximo dois filhos, a Árvore B permite que um nó tenha um número variável de filhos, dentro de um intervalo definido. A busca em uma Árvore B é similar à busca em árvores binárias. No entanto, ao invés de se decidir apenas entre esquerda ou direita, é necessário escolher entre múltiplos caminhos, de acordo com os filhos do nó.
A inserção, por sua vez, pode requerer a divisão do nó caso ele esteja cheio. Se o nó-alvo da inserção tem espaço, a chave é diretamente inserida. Caso contrário, o nó é dividido para acomodar a nova chave e manter o balanceamento da árvore. Já a remoção de uma chave é mais direta se ela estiver em um nó folha. Entretanto, quando a chave a ser removida está em um nó interno, diversos cenários precisam ser considerados para assegurar que a árvore permaneça balanceada após a operação.
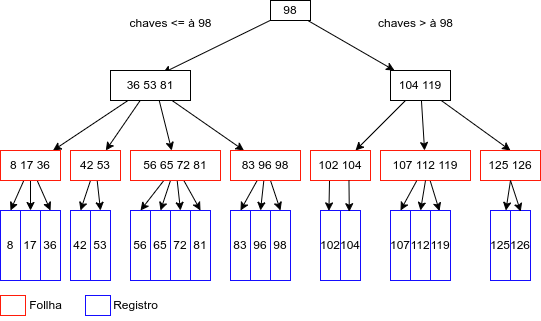
- Características e Vantagens
- Balanceamento e Estrutura Flexível
- A Árvore B é intrinsicamente balanceada, garantindo que todos os caminhos da raiz até qualquer folha tenham o mesmo comprimento. Além disso, ao contrário das árvores binárias, os nós podem ter um número variável de filhos, proporcionando uma estrutura adaptável.
- Eficiência em Operações
- A combinação do balanceamento com o alto fator de ramificação resulta em uma altura de árvore geralmente reduzida, mesmo com muitos elementos. Isso permite buscas, inserções e remoções eficientes
- Otimização de Acessos ao Disco
- A Árvore B minimiza os acessos ao disco ao agrupar vários elementos em um único nó, tornando as operações de leitura e escrita mais econômicas e eficientes.
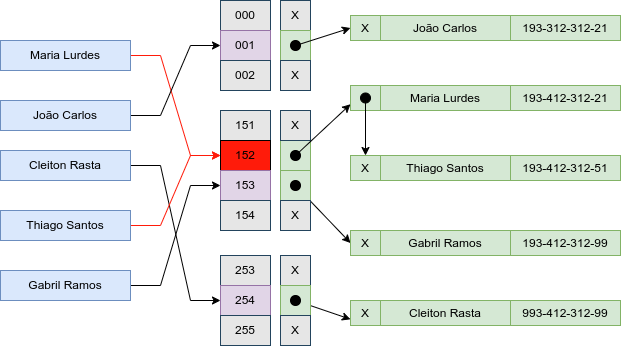
Índice Hashing
- Funcionamento
- Características e Vantagens
- Acesso quase imediato
- O índice de hashing é especialmente eficiente para recuperações pontuais onde apenas um registro é buscado. Quando a função de hash é bem projetada e a tabela de hash não está sobrecarregada, a localização de um registro pode ser quase imediata.
- Hashing Dinâmico
- O hashing extensível e o hashing linear são métodos para tratar colisões (quando dois registros têm o mesmo valor de hash) e para adaptar-se ao crescimento do banco de dados.
- Limitação para consultas de intervalo
- A principal desvantagem é que os índices de hash não são adequados para consultas de intervalo. Por exemplo, encontrar todos os registros entre dois valores seria ineficiente, pois não há ordem lógica no hashing como na B-Tree.
O índice hashing é uma técnica de armazenamento e recuperação de dados que busca proporcionar acesso direto aos registros em um banco de dados. Esta técnica emprega uma função hash, que converte uma chave de entrada em um endereço específico em uma estrutura denominada tabela hash. A intenção é que a função distribua as chaves de forma uniforme pela tabela, evitando, assim, a superposição de chaves no mesmo endereço, fenômeno conhecido como colisão.
Quando ocorre uma colisão, ou seja, quando duas chaves distintas são mapeadas para o mesmo endereço na tabela hash, é necessário adotar estratégias para solucionar o conflito. Entre as abordagens comuns estão o encadeamento, em que cada endereço da tabela contém uma lista de entradas, e a sondagem, que busca sequencialmente o próximo endereço vazio para alocação. Estas estratégias garantem que cada chave tenha um local apropriado na estrutura, mesmo em situações de colisão.
|
Com intuito de apoiar o aprendizado em Banco de Dados, sugere-se assistir a videoaula para o aperfeiçoamento no conhecimento deste conteúdo. |
Índices Multiníveis
- Funcionamento
Os índices multiníveis são estruturas de índices hierárquicas que facilitam o acesso rápido a registros em grandes bancos de dados. O conceito central é semelhante ao de um índice de um livro. No primeiro nível, o índice aponta para um intervalo de chaves em um nível inferior. Esse nível inferior pode, por sua vez, apontar para outro nível de índices ou diretamente para os registros. Assim, os níveis superiores do índice oferecem uma visão mais generalizada, enquanto os níveis inferiores fornecem detalhamento, até que se chegue aos registros reais.
Este design hierárquico facilita a localização rápida de registros, especialmente em grandes conjuntos de dados. Começando pelo nível mais alto, o sistema pode determinar em qual intervalo a chave desejada se encontra e, em seguida, passar ao nível subsequente. Este processo é repetido até que o registro correspondente seja localizado, permitindo que a busca seja realizada de forma eficiente através da redução progressiva do espaço de busca.
- Características e Vantagens
- Buscas Otimizadas
- A busca pode ser feita em vários níveis, tornando-se mais rápida, especialmente quando se lida com uma grande quantidade de dados.
- Menor Espaço de Armazenamento:
- Ao contrário de manter um índice único e massivo, os índices multiníveis podem ser mais compactos e ocupar menos espaço.
- Minimização do Overhead
- Ao reduzir o espaço de busca em cada etapa, os índices multiníveis minimizam o overhead de I/O e melhoram a performance geral de buscas.
|
Com intuito de apoiar o aprendizado em Banco de Dados, sugere-se assistir a videoaula para o aperfeiçoamento no conhecimento deste conteúdo. |
É essencial entender que não há uma técnica superior universalmente; cada uma se destaca em determinados cenários. Assim, ao projetar um sistema ou aplicativo, é vital analisar cuidadosamente as necessidades e características dos dados para escolher a técnica de indexação mais apropriada. Ao fazer a escolha correta, os benefícios em termos de desempenho e eficiência podem ser significativos.
|
Com intuito de apoiar o aprendizado em Banco de Dados, sugere-se assistir a videoaula para o aperfeiçoamento no conhecimento deste conteúdo. |
O exemplo a seguir demonstrará a criação e utilização de
índices em uma tabela
clientes no MySQL.
CREATE TABLE CLIENTES (
id INT AUTO_INCREMENT PRIMARY KEY,
nome VARCHAR(255),
email VARCHAR(255) NOT NULL,
telefone VARCHAR(15)
);
INSERT INTO CLIENTES (nome, email, telefone) VALUES
('Ana Silva', 'ana.silva@email.com', '1234-5678'),
('João Pereira', 'joao.pereira@email.com', '2345-6789'),
('Maria Oliveira', 'maria.oliveira@email.com', '3456-7890');
CREATE INDEX Cliente_Email_IDX ON CLIENTES(email);
Com a criação do índice `idx_email`, ao executar uma consulta como:
SELECT * FROM CLIENTES WHERE email = 'ana.silva@email.com';
O MySQL utiliza o índice `Cliente_Email_IDX` para localizar diretamente o registro associado ao email especificado, proporcionando uma busca mais eficiente em comparação com a varredura completa da tabela.
Para deletar o index utiliza-se a instrução DDL `DROP INDEX` por exemplo
DROP INDEX Cliente_Email_IDX ON CLIENTES;
É importante observar que, embora índices acelerem consultas, eles consomem espaço em disco e podem impactar operações de inserção, atualização ou deleção, pois o índice precisa ser mantido atualizado. Assim, é essencial avaliar cuidadosamente quais colunas serão indexadas.
O mundo dos bancos de dados é complexo e variado. Cada tipo de índice tem seus próprios méritos e é mais adequado para certos tipos de operações ou conjuntos de dados. Escolher o índice correto, ou uma combinação de índices, é crucial para garantir que o banco de dados funcione de maneira otimizada e eficiente.
|
Com intuito de apoiar o aprendizado em Banco de Dados, sugere-se assistir a videoaula para o aperfeiçoamento no conhecimento deste conteúdo. |
Atividade de Fixação
No intuito de fixar a aprendizagem iniciada por meio deste módulo e verificar como está sua compreensão sobre o mesmo, são sugeridos alguns exercícios de fixação para serem resolvidos. Clique no link de exercícios ao lado, pois será por meio dele iniciada a lista de exercícios sobre os conteúdos estudados até este