INSTRUÇÕES SQL
SQL é uma linguagem de consulta estruturada usada por programadores e DBAs para executar consultas e comandos nos principais SGBDs do mercado. É por meio dela que criamos tabelas, colunas, índices, atribuímos permissões a usuários e realizamos consultas a dados. A linguagem SQL é organizada em subconjuntos, cada um com propósitos bem definidos. Alguns desses subconjuntos incluem:
- DDL (Data Definition Language) - usado para definir as estruturas de dados, como criar, alterar e excluir tabelas e índices.
- DML (Data Manipulation Language) - usado para manipular os dados armazenados nas tabelas, como inserir, atualizar e excluir registros.
- DCL (Data Control Language) - usado para controlar o acesso aos dados do banco de dados, adicionando e removendo permissões de acesso. Isso será visto no conteúdo deControle de acesso
Seleção de Dados
O comando SQL que nos permite realizar consultas ao banco de dados é o comando SELECT. Como dissemos, o comando SELECT serve para realizar consultas ao banco de dados (como um todo), e não somente a uma tabela. É por isto que a instrução abaixo funciona apesar de não estarmos consultando nenhuma tabela.
SELECT 4/2;
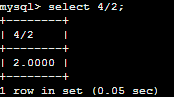
Nesta instrução estamos consultando o banco de dados sobre a divisão dos valores 4 por 2, e ele retornou o valor 2.0000, que é o resultado da divisão. Depois de esclarecido isto, vamos ver a sintaxe básica do comando SELECT.
SELECT (colunas) FROM nome_tabela WHERE definição_where
Código que será utilizado para explicação do conteúdo:
create database locadora; use locadora; CREATE TABLE `filmes` ( `id` int(10) unsigned NOT NULL, `titulo` varchar(80) NOT NULL, `ano` int(4) unsigned NOT NULL, `diretor` varchar(80) NOT NULL, PRIMARY KEY (`id`) )AUTO_INCREMENT=4; INSERT INTO `filmes` VALUES (1, 'King Kong', 2006, 'Peter Jackson'); INSERT INTO `filmes` VALUES (2, 'Guerra dos Mundos', 2005, 'Steven Spielberg'); INSERT INTO `filmes` VALUES (3, 'Harry Potter', 2006, 'Mike Newell');
Vamos para um exemplo prático em nossa tabela filmes.
SELECT * FROM filmes;
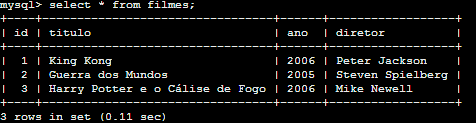
O * (asterisco) substitui os nomes de todas colunas, e todas serão selecionadas para o resultado da consulta. A instrução FROM indica de qual tabela estamos buscando dados, no nosso exemplo a tabela filmes. Como a instrução WHERE (que funciona como um filtro) não foi declarada, não temos nenhuma restrição aos dados pesquisados, e a consulta retornará todo o conteúdo da tabela filmes. Caso não fosse de nosso desejo mostrar todas as colunas no resultado da consulta, bastaria nomear as colunas que deveriam aparecer no lugar do * (asterisco) e separadas por vírgula.
Vamos agora realizar a mesma consulta só que com um filtro, uma restrição aos dados que serão exibidos no resultado da consulta. Desta vez também selecionaremos apenas as colunas id, titulo e ano para o resultado.
SELECT id,titulo,ano FROM filmes WHERE ano = 2006;
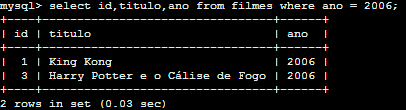
A instrução SELECT id,titulo,ano FROM filmes WHERE ano = 2006 possui os principais pontos de uma consulta. Determinamos quais colunas (campos) deveriam aparecer no resultado da consulta, e filtramos o resultado para aparecerem apenas os registros cujo campo ano tenha o valor igual a 2006. Note que apenas os filmes de 2006 estão presentes no resultado da consulta. O filtros da cláusula WHERE podem ser mais complexos e determinarem mais de uma condição, como no exemplo a seguir.
SELECT id,titulo,ano FROM filmes WHERE ano = 2006 AND titulo = 'King Kong';
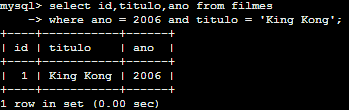
Neste caso selecionamos apenas os registros que possuem o ano igual a 2006 e o titulo igual a King Kong. Neste caso a cláusula WHERE é auxiliada pelo AND que cria uma interseção no resultado da consulta entre os registro que possuem o ano 2006 e o titulo King Kong. Podemos também criar uma união entre os resultados com OR.
SELECT id,titulo,ano FROM filmes WHERE ano = 2005 OR titulo = 'King Kong';
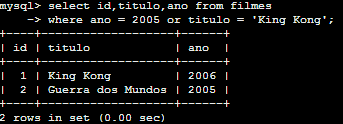
Aqui aparecem tanto o registro que possui o título King Kong como o registro do filme de 2005, ou seja, uma união.
O comando sql SELECT é de fundamental importância para qualquer banco de dados, e no MySQL não é diferente, ele constitui uma ferramenta poderosa para recuperarmos dados importante e localizarmos apenas o que nos interessa no momento. O que vimos aqui foram apenas os tipos de consultas mais básicas do comando SELECT, mas suficientes para que possamos começar a explorar melhor todo o potencial do MySQL.
Atividade de Fixação
No intuito de fixar a aprendizagem iniciada por meio deste módulo e verificar como está sua compreensão sobre o mesmo, são sugeridos alguns exercícios de fixação para serem resolvidos. Clique no link de exercícios ao lado, pois será por meio dele iniciada a lista de exercícios sobre os conteúdos estudados até este momento. Boa revisão sobre os mesmos!!
Alteração de Dados
O comando SQL que nos permite atualizar dados no MySQL é o comando UPDATE. A sintaxe básica do comando UPDATE é a seguinte:
UPDATE nome_tabela SET nome_coluna1=expr1, nome_coluna2=expr2 WHERE definição_where
UPDATE é aplicado a uma tabela e a cláusula SET atribui a um campo o valor de uma expressão que pode ou não conter o valor de um campo da própria tabela. A cláusula WHERE restringe as atualizações apenas aos registro que satisfaçam suas condições.
A partir da MySQL Versão 4.0.4, você também pode realizar operações UPDATE que cobrem múltiplas tabelas.
Código utilizado para explicação do conteúdo:
create database locadora; use locadora; CREATE TABLE `filmes` ( `id` int(10) unsigned NOT NULL, `titulo` varchar(80) NOT NULL, `ano` int(4) unsigned NOT NULL, `diretor` varchar(80) NOT NULL, PRIMARY KEY (`id`) )AUTO_INCREMENT=4; INSERT INTO `filmes` VALUES (1, 'King Kong', 2006, 'Peter Jackson'); INSERT INTO `filmes` VALUES (2, 'Guerra dos Mundos', 2005, 'Steven Spielberg'); INSERT INTO `filmes` VALUES (3, 'Harry Potter', 2006, 'Mike Newell');
Vamos para um exemplo prático. Primeiro visualizaremos que dados temos em nossa tabela filmes :
SELECT * FROM filmes;
Vamos supor que desejássemos mudar todos os filmes para o ano de '2006', o comando UPDATE seria o seguinte:
UPDATE filmes SET ano=2006;

O resultado do comando UPDATE notifica que três linhas combinaram com o comando (uma vez que temos três registros na tabela e não utilizamos a cláusula WHERE), e destas três, uma foi alterada (atualizada). Vamos ver como ficaram os registros:
SELECT * FROM filmes;
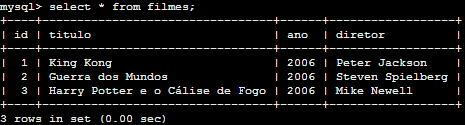
Perceba que todos os filmes agora tem o valor '2006' no campo 'ano'. Os filmes que já tinham o valor '2006' para 'ano' foram ignorados pelo comando UPDATE. Neste primeiro exemplo não utilizamos a cláusula WHERE, e o comando UPDATE tentou mudar todo e qualquer registro para o ano de '2006', é claro que isto não é um comportamento ideal para a maioria de nossas necessidades. Vamos realizar uma atualização de um só registro desta vez. Para isto vamos restringir o comando UPDADE com a cláusula WHERE.
UPDATE filmes SET ano=ano-1 WHERE id=2;

Neste exemplo a instrução 'WHERE id=2' restringe a atualização apenas ao registro que possuir a chave primária 'id' com o valor '2', no caso o filme 'Guerra dos Mundos'. Outro ponto importante neste exemplo é que utilizamos o próprio valor do campo 'ano' para atualizá-lo. 'SET ano=ano-1' atualiza o valor de 'ano' para '2005', uma vez que 'ano' tinha o valor de '2006' (2006 - 1 = 2005). A tabela filmes ficou com os seguintes dados:
SELECT * FROM filmes;
O comando SQL UPDATE utilizado com a cláusula WHERE torna-se uma ferramenta poderosa para desenvolvedores manipularem dados no MySQL. O fato de a cláusula SET aceitar atribuição de valores de expressões possibilita que trabalhemos com os valores já existentes no registro manipulado, o que também expande nosso controle sobre os dados.
Atividade de Fixação
No intuito de fixar a aprendizagem iniciada por meio deste módulo e verificar como está sua compreensão sobre o mesmo, são sugeridos alguns exercícios de fixação para serem resolvidos. Clique no link de exercícios ao lado, pois será por meio dele iniciada a lista de exercícios sobre os conteúdos estudados até este momento. Boa revisão sobre os mesmos!!
Inserção de Dados
A síntese básica do comando INSERT é a seguinte:
INSERT INTO <nome_tabela> <[(nome_coluna,...)]> VALUES <valores>
Código utilizado para explicação do conteúdo:
create database locadora; use locadora; CREATE TABLE `filmes` ( `id` int(10) unsigned NOT NULL, `titulo` varchar(80) NOT NULL, `ano` int(4) unsigned NOT NULL, `diretor` varchar(80) NOT NULL, PRIMARY KEY (`id`) )AUTO_INCREMENT=4; INSERT INTO `filmes` VALUES (1, 'King Kong', 2006, 'Peter Jackson'); INSERT INTO `filmes` VALUES (2, 'Guerra dos Mundos', 2005, 'Steven Spielberg'); INSERT INTO `filmes` VALUES (3, 'Harry Potter', 2006, 'Mike Newell');
Vamos inserir os dados de um filme em nossa tabela.
insert into filmes (id,titulo,ano,diretor) values (0,'King Kong',2006,'Peter');

Quando é criada a tabela filmes é definida a coluna id como tendo a característica de ser auto_increment, ou seja, seu valor é incrementado automaticamente, não é necessário preocupar com o valor inserido por último para decidir qual o valor a ser inserido agora. Com esta característica pode-se criar sequências de valores como 1,2,3,4,5,6... Para aproveitar esta facilidade não se pode atribuir um valor válido a coluna id, deve-se inserir 0 ou NULL para que o banco de dados saiba que deseja-se que ele calcule sozinho o próximo valor válido.
Interessante ressaltar que valores do tipo texto (string) são colocados entre aspas (simples ou dupla). Poderia, também, inserir dados omitindo os nomes das colunas e colocando apenas os valores no comando, desde que os valores estejam na mesma sequência das colunas na tabela.
insert into filmes values (null,'Guerra',2005,'Steven');

Note que desta vez não foi colocado os nomes das colunas antes da instrução VALUES. Outra mudança que foi feita foi atribuir o valor null a coluna id. Observe como está a tabela no momento com o auxílio do comando SELECT.
SELECT * FROM filmes;
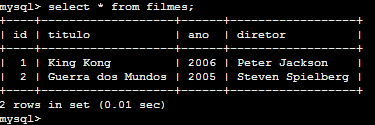
Observe que a coluna id contém uma sequência de valores, sequência esta gerada automaticamente pelo banco de dados.
Atividade de Fixação
No intuito de fixar a aprendizagem iniciada por meio deste módulo e verificar como está sua compreensão sobre o mesmo, são sugeridos alguns exercícios de fixação para serem resolvidos. Clique no link de exercícios ao lado, pois será por meio dele iniciada a lista de exercícios sobre os conteúdos estudados até este momento. Boa revisão sobre os mesmos!!
Exclusão de Dados
O comando SQL que nos permite excluir dados no MySQL é o comando DELETE. A sintaxe básica do comando DELETE é a seguinte:
Código utilizado para explicação do conteúdo:
DROP TABLE IF EXISTS `filmes`; CREATE TABLE `filmes` ( `id` int(10) unsigned NOT NULL, `titulo` varchar(80) NOT NULL, `ano` int(4) unsigned NOT NULL, `diretor` varchar(80) NOT NULL, PRIMARY KEY (`id`) ) AUTO_INCREMENT=4 ; INSERT INTO `filmes` VALUES (1, 'King Kong', 2006, 'Peter Jackson'); INSERT INTO `filmes` VALUES (2, 'Guerra dos Mundos', 2005, 'Steven Spielberg'); INSERT INTO `filmes` VALUES (3, 'Harry Potter', 2006, 'Mike Newell');
DELETE FROM <table_name> [WHERE <definição_where>]
O comando DELETE é aplicado a uma tabela e pode ou não ter uma cláusula WHERE que restringe os registros nos quais ele atuará. Este comando retorna o número de registros excluídos da tabela. Se não for especificada uma cláusula WHERE o comando DELETE apagará todos os registros da tabela. Neste caso, no MySQL 3.23, o comando retorna zero.
A partir do MySQL 4.0.0 a exclusão em multi-tabelas é suportada. Vamos para um exemplo prático. Primeiro visualizaremos que dados temos em nossa tabela filmes:
Como já havíamos visto em artigos anteriores o comando SELECT * FROM filmes retorna todos os registros da tabela filmes. Neste caso temos três registros de filmes. Para ilustrar a utilização mais comum do comando DELETE vamos excluir um destes registros com o uso de algum critério. Poderíamos ter um critério único, que excluiria apenas um registro (por exemplo usando o campo id), ou um critério múltiplo, que poderia apagar mais de um registro (por exemplo, neste caso, usando o campo ano). Vamos optar por usar o campo ano e excluir todos os filmes de anos anteriores a '2006', o comando seria o seguinte:
DELETE FROM filmes WHERE ano < 2006;

O comando DELETE foi executado com sucesso ("Query Ok") e afetou apenas uma linha (registro) da tabela, ou seja, existia apenas um filme na tabela com data anterior a '2006'.
Vamos ver como ficaram os registros:
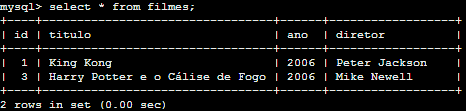
Fica claro que agora só temos filmes do ano de '2006' na tabela. Vamos agora apagar um registro com base em um campo string. Executaremos o seguinte comando:
DELETE FROM filmes WHERE diretor LIKE '%Jackson'

Neste caso o comando DELETE excluiria todos os registros cujo campo diretor terminasse com o sobrenome 'Jackson' (todos os campos que se parecessem com isto). Novamente o comando retornou sucesso e avisou que uma linha foi afetada, ou seja, tínhamos um registro que satisfazia a condição.
O comando SQL DELETE nos possibilita excluir, com enorme precisão, registros de uma tabela MySQL. Esta precisão se deve ao fato dele aceitar a cláusula WHERE e todos os benefícios de filtragem de dados que ela possui. Sem o uso de WHERE, temos um comando capaz de excluir de uma só vez todos os dados de uma tabela, algo que não ocorre com frequência, mas que pode ser útil em determinadas circunstâncias, principalmente quando desejamos saber quantos registro foram apagados.
Atividade de Fixação
No intuito de fixar a aprendizagem iniciada por meio deste módulo e verificar como está sua compreensão sobre o mesmo, são sugeridos alguns exercícios de fixação para serem resolvidos. Clique no link de exercícios ao lado, pois será por meio dele iniciada a lista de exercícios sobre os conteúdos estudados até este momento. Boa revisão sobre os mesmos!!
Instruções DDL
Descrição de Dados de Linguagem (DDL) é uma sintaxe semelhante a uma linguagem de programação de computador para a definição de estruturas de dados, especialmente esquemas de banco de dados.
Nos modelos de bases de dados relacionais, a tabela é um conjunto de dados dispostos em número finito de colunas e número ilimitado de linhas (ou tuplas).
As colunas são tipicamente consideradas os campos da tabela, e caracterizam os tipos de dados que deverão constar na tabela (numéricos, alfa-numéricos, datas, coordenadas, etc). O número de linhas pode ser interpretado como o número de combinações de valores dos campos da tabela, e pode conter linhas idênticas, dependendo do objetivo. A forma de referenciar inequivocamente uma única linha é através da utilização de uma chave primária.
O número de tuplas de uma tabela é virtualmente ilimitado, o que torna as pesquisas por valor potencialmente muito lentas. Para permitir agilizar estas consultas, podem ser associados índices à tabela, que são estruturas de dados independentes da forma e ordem como estão armazenados os dados, embora tenham relação direta com os mesmos. Como consequência, a cada alteração de dados, irá corresponder uma (ou mais) alterações em cada um dos índices, aumentando o esforço necessário ao sistema gestor de base de dados (SGBD) para gerir essa alteração, motivo pelo qual os índices não existam naturalmente para cada coluna.
A síntese de criação de tabelas do MySQL é a seguinte:
CREATE TABLE <nome_tabela>;
Para criar uma tabela basta executar a seguinte parte da síntese: CREATE TABLE nome_tabela. Mas é mais comum criar a tabela já acompanhada de seus campos (fields). Veja o exemplo na tabela filmes com os seguintes campos:
- id - campo de identificação;
- titulo - titulo do filme;
- ano - Ano de produção;
- diretor - diretor do filmes;
Para isto deve executar o seguinte comando:
create table filmes( id int(10) unsigned not null auto_increment, titulo varchar(80) not null, ano int(4) unsigned not null, diretor varchar(80) not null, primary key (id));
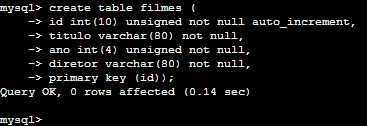
No campo id por exemplo o tipo é int(10) com o modificador unsigned, ele não aceita valores nulos (not null) e é auto_increment, ou seja, seu valor é definido automaticamente, aumentando de 1 (um) em 1 (um) toda vez que um novo registro é adicionado. Para fazer uso desta funcionalidade é necessário adicionar o valor 0 ou null neste campo. No campo titulo o tipo varchar(80) o que significa que este campo aceita caracteres alfanuméricos num máximo determinado por 80. O campo também não pode ser nulo.
A instrução ALTER TABLE é usado para adicionar, excluir ou modificar as colunas de uma tabela existente. Para adicionar uma coluna em uma tabela, use a seguinte sintaxe:
ALTER TABLE <table_name> ADD <column_name> datatype;
Para excluir uma coluna de uma tabela, use a seguinte sintaxe (note que alguns sistemas de banco de dados não permitem excluir uma coluna):
ALTER TABLE <table_name> DROP COLUMN <column_name>;
Olhe o exemplo:

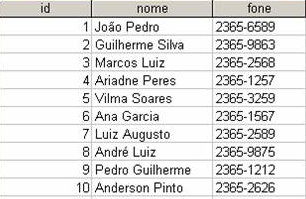
Agora, ao adicionar uma coluna chamada "DataNiver" no "Pessoas" da tabela. A seguinte instrução SQL deve ser usada:
ALTER TABLE Pessoas ADD DataNiver date;
Observe que a nova coluna, "DataNiver", é do tipo data e vai realizar uma data. O tipo de dados especifica que tipo de dados da coluna pode conter. Para uma referência completa de todos os tipos de dados disponíveis em MS Access, MySQL e SQL Server. A table "pessoas" agora fica assim:

Em seguida, tentando excluir a coluna denominada "DataNiver" no "Pessoas" da tabela. A seguinte instrução SQL deve ser usada:
ALTER TABLE Pessoas DROP COLUMN DataNiver;
A tabela "pessoas" agora fica assim:
Atividade de Fixação
No intuito de fixar a aprendizagem iniciada por meio deste módulo e verificar como está sua compreensão sobre o mesmo, são sugeridos alguns exercícios de fixação para serem resolvidos. Clique no link de exercícios ao lado, pois será por meio dele iniciada a lista de exercícios sobre os conteúdos estudados até este momento. Boa revisão sobre os mesmos!!
Subquerys
Join
Um SQL cláusula de junção combina registros de duas ou mais tabelas em um banco de dados. Ele cria um conjunto que pode ser salvo como uma tabela ou usado como ele é. Uma união é um meio para combinar campos de duas tabelas usando valores comuns a cada um. Como um caso especial, uma tabela (tabela base, visão ou tabela unida) pode juntar-se a si mesma em uma auto-associação. Um programador escreve um predicado de junção para identificar os registros de união. Se o predicado avaliado for verdadeiro, o registro é combinado e então produzido no formato esperado, um conjunto de registros ou uma tabela temporária.
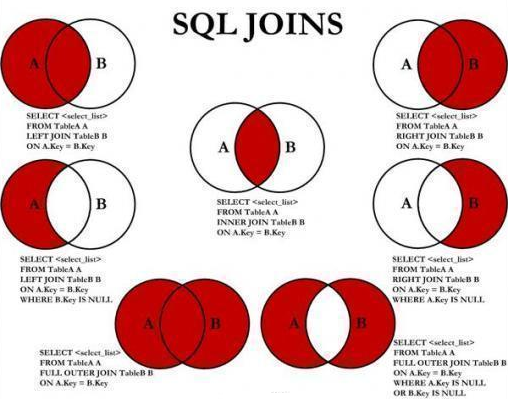
Figura ilustrativa do comando Join
Bancos de dados relacionais são frequentemente normalizados para eliminar a duplicação de informações quando os objetos podem ter relações um-para-muitos. Por exemplo, um Departamento pode ser associado com muitos empregados diferentes. A junção de duas tabelas efetivamente cria outra tabela que combina informações de ambas as tabelas. Isto é, em alguma despesa em termos do tempo que leva para computar a união. Embora seja também possível simplesmente manter uma tabela desnormalizada, se a velocidade é importante, a informação pode ter duplicado espaço extra, e adicionar o custo e a complexidade da manutenção da integridade dos dados se os dados que estão duplicados sofrerem alterações posteriores. Todas as explicações posteriores sobre tipos de junção neste artigo fazem uso das seguintes duas tabelas. As linhas nestas tabelas servem para ilustrar o efeito de diferentes tipos de junta e juntar-predicados. Nas tabelas a seguir a coluna DepartamentoID da tabela Departamento (que pode ser designado como Departmento.DepartamentoID) é a chave principal, enquanto Employee.DepartamentoID é uma chave estrangeira.
Para o entendimento do conteúdo use este código:
CREATE DATABASE EXER;
USE EXER;
CREATE TABLE departamento (
DepartamentoID INT,
nomeDepartamento VARCHAR(20)
);
CREATE TABLE empregado (
Sobrenome VARCHAR(20),
DepartamentoID INT
);
INSERT INTO departamento(DepartamentoID, nomeDepartamento) VALUES(31, 'Sales');
INSERT INTO departamento(DepartamentoID, nomeDepartamento) VALUES(33, 'Engineering');
INSERT INTO departamento(DepartamentoID, nomeDepartamento) VALUES(34, 'Clerical');
INSERT INTO departamento(DepartamentoID, nomeDepartamento) VALUES(35, 'Marketing');
INSERT INTO empregado(Sobrenome, DepartamentoID) VALUES('Rafferty', 31);
INSERT INTO empregado(Sobrenome, DepartamentoID) VALUES('Jones', 33);
INSERT INTO empregado(Sobrenome, DepartamentoID) VALUES('Steinberg', 33);
INSERT INTO empregado(Sobrenome, DepartamentoID) VALUES('Robinson', 34);
INSERT INTO empregado(Sobrenome, DepartamentoID) VALUES('Smith', 34);
INSERT INTO empregado(Sobrenome, DepartamentoID) VALUES('John', NULL);
Uma junção interna é a operação de associação mais comumente usada em aplicações e pode ser considerada como o padrão de junção do tipo. INNER JOIN cria uma nova tabela de resultados através da combinação de valores das colunas de duas tabelas (A e B) com base na junção-predicado. A consulta compara cada linha de A com cada linha de B para encontrar todos os pares de linhas que satisfazem a junção-predicado. Quando a junção-predicado é satisfeita, os valores de coluna para cada par correspondente de linhas de A e B são combinados em uma linha do resultado. O resultado da junção pode ser definido como o resultado do primeiro "tomar o produto cartesiano" (ou CROSS JOIN) de todos os registros nas tabelas (combinando cada registro na tabela A com cada registro na tabela B) - em seguida, retornar todos os registros que satisfazem o predicado de junção. Implementações reais SQL normalmente usam outras abordagens, como uma junção de hash ou uma espécie de mesclagem "juntar sempre que possível", uma vez que o cálculo do produto cartesiano é muito ineficiente. O SQL especifica duas diferentes formas sintáticas para expressar junta: "join explícito notação" e "implícita juntar notação". O "notação de junção explícita" usa a palavra-chave Cadastre-se para especificar a tabela para entrar, e a palavra-chave ON para especificar os predicados para a junção, como no exemplo a seguir:
SELECT * FROM empregado INNER JOIN departamento ON empregado.DepartamentoID = departamento.DepartamentoID;
O "notação junção implícita" simplesmente lista as tabelas para unir, na cláusula FROM da instrução SELECT, usando vírgulas para separá-los. Assim, prevê-se uma junção cruzada, e a cláusula WHERE pode aplicar filtros adicionais-predicados (que funcionam comparativamente aos join-predicados na notação explícita). O exemplo a seguir é equivalente ao anterior, mas desta vez utilizando a notação de junção implícita:
SELECT * FROM empregado, departamento WHERE empregado.DepartamentoID = departamento.DepartamentoID;
Group By
Tudo que foi feito até aqui tratava todos os dados de uma relação como um único grupo de dados, mas as vezes é necessário dividir estas relações em grupos menores. Procurando realizar estas divisões nos dados é que se pode incluir a cláusula GROUP BY em uma instrução SELECT. É possível aplicar uma clausula GROUP BY em uma seleção e usar uma função de grupo para sumarizar os valores de cada um dos grupos formados.

Suponha que a consulta abaixo seja executada e o resultado seja apresentado a seguir.
SELECT SILGA, COUNT(SIGLA) FROM CIDADE GROUP BY SIGLA;
A relação CIDADE foi dividida em três grupos por meio da sigla, onde são consideradas somente as siglas que estão cadastradas e são apresentadas por meio de seleção do atributo SIGLA, enquanto que a função COUNT, sobre a sigla, mostra a quantidade de tuplas que existe em cada sigla (alguns grupos).
Sempre que existir um ou mais atributos individuais na seleção, juntamente com a aplicação de funções de grupo, sera necessário incluir estes atributos no grupo por meio da cláusula GROUP BY.
SELECT SIGLA, COUNT(SIGLA) FROM CIDADE GROUP BY SIGLA;
A seleção sem especificação de nenhum atributo individual também é possível, mas será realizada por toda a relação se não for especificada a cláusula GROUP BY.
O atributo especificado no GROUP BY não precisa estar no SELECT, mas normalmente seu resultado fica sem sentido devido a dificuldade de compreensão dos dados agrupados.
SELECT COUNT(SIGLA) FROM CIDADE GROUP BY SIGLA;
Pode também existir a necessidade de agrupar mais que um atributo, onde uma relação é agrupada primeiro por um atributo e dentro deste também é realizado o agrupamento por um outro atributo. Imagine o exemplo:
SELECT DEPARTAMENTO, EMPREGADO, SUM(SALARIO) FROM EMPREGADO GROUP BY DEPARTAMENTO, EMPREGADO;
Sempre que existir um ou mais atributos individuais na seleção, juntamente com a aplicação de funções de grupo, será necessário incluir estes atributos no grupo por meio da cláusula GROUP BY.
SELECT SIGLA, COUNT(SIGLA) FROM CIDADE GROUP BY SIGLA;
A seleção sem especificação de nenhum atributo individual também é possível, mas será realizada por toda a relação se não for especificada a cláusula GROUP BY. Observe os resultados em seu BD aplicando as duas sugestões a seguir.
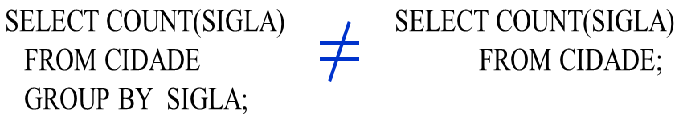
Order By
Uma cláusula ORDER BY no SQL especifica que uma instrução SQL SELECT retorna um conjunto de resultados com as linhas que estão sendo classificadas pelos valores de uma ou mais colunas. Os critérios de classificação não têm de ser incluídos no conjunto de resultados. Os critérios de classificação podem ser expressões, incluindo - mas não limitado a - nomes de colunas, funções definidas pelo usuário, operações aritméticas, ou expressões caso. As expressões são avaliadas e os resultados obtidos são utilizados para a classificação, isto é, os valores armazenados na coluna, ou o resultado da chamada de função. A apresentação dos dados recupereados pelo SELECT pode ser classificada, onde esta classificação será ascendente (crescente) ou descendente (decrescente).
Para isso inclui-se a cláusula ORDER BY no final da instrução de consulta (SELECT).
SELECT NOME FROM ESTADOS
ORDER BY NOME ASC;
Uma classificação com mais que um atributo pode ser feita com a especificação ordenada de quais os atributos a serem usados na classificação e a ordem de prioridade para cada um.
Os atributos devem ser especificados, separados por vírgula e devem estar em ordem de prioridade conforme sua especificação na cláusula ORDER BY, onde o primeiro atributo especificado será classificado primeiramente e o segundo, respeitando a classificação do primeiro, será classificado em seguida, dentro da primeira classificação.
SELECT nome
FROM empregado
WHERE salario < 0
ORDER BY nome, salario;
Observação:
A primeira classificação será feita por nome, e dentro da classificação por nome será feita por salário.
Sub Consultas
Uma subconsulta, ou consulta interna consiste em uma instrução SELECT incorporada em uma cláusula de outra instrução DML. Pode-se desenvolver instruções sofisticadas por meio da incorporação de subconsultas simples. Elas são possíveis de ser inseridas nas cláusulas:
- WHERE
- HAVING
- FROM
Apesar de todas estas possibilidades, as subconsultas são normalmente inseridas na cláusula WHERE de instruções DML (Data Manipulation Language).
Observe a forma geral da subconsulta para um SELECT:
SELECT <lista_atributos>
FROM <relação>
WHERE <operando operador> ( SELECT <lista_atributo>
FROM <relação>
WHERE <condições> );
Exemplo
Suponha que exista a necessidade de descobrir quem recebe salário maior que o empregado padrão na empresa (código 325). Primeiramente é necessário elaborar uma consulta para descobrir qual o salário de Paulo (325) e depois uma outra consulta para descobrir quem recebe mais que tal quantia. Para isso é possível combinar duas consultas, colocando "uma dentro da outra".
SELECT F.ID_FUNCIONAL, F.NOME
FROM FUNCIONARIO F
WHERE SALARIO > ( SELECT FU.SALARIO
FROM FUNCIONARIO FU
WHERE FU.ID_FUNCIONAL = 325 );
A elaboração de uma consulta com subconsulta deve respeitar as seguintes diretrizes para ser realizada corretamente:
- Subconsulta deve estar entre parênteses;
- Coloque-a do lado direito do operador de comparação;
- Subconsulta não deve possuir uma cláusula ORDER BY;
- Respeitar as classes de operadores de comparação nas subconsultas;
Atividade de Fixação
No intuito de fixar a aprendizagem iniciada por meio deste módulo e verificar como seu entendimento sobre este conteúdo está, estão sendo sugeridos alguns exercícios de fixação para serem resolvidos. Clique no link de exercícios ao lado, pois será por meio dele iniciada a lista de exercícios sobre os conteúdos estudados até este momento nesta disciplina.